Sygeplejersken
Sådan skrives redelige tabeller
Vi er omgivet af tal i aviser og inden for det medicinske og sygeplejefaglige felt. Vi argumenterer ved hjælp af tal og statistik – men det er bestemt ikke ligegyldigt, hvordan tallene bliver regnet ud og præsenteret for læserne. Her gives en vejledning i, hvordan datamateriale bør præsenteres i artikler til 'Sygeplejersken'. Artiklen er et led i uddannelsesserien, denne gang med stof hentet hos en sociolog.
Sygeplejersken 1997 nr. 11, s. 24-27
Af:
Merete Watt Boolsen, lektor, mag.scient.soc. et lic.

 Principielt er der ingen forskel på konstruktionen af tabeller med få eller mange observationer, men observationsmængden gør en forskel, når man giver sig til at regne videre – eksempelvis oversætte til procenter eller anvende statistiske test. Illustration: Claus Bigum.
Principielt er der ingen forskel på konstruktionen af tabeller med få eller mange observationer, men observationsmængden gør en forskel, når man giver sig til at regne videre – eksempelvis oversætte til procenter eller anvende statistiske test. Illustration: Claus Bigum.
'Sygeplejersken' publicerer i stigende omfang artikler, der omhandler undersøgelser af sygeplejerskers iagttagelser af patienter, sig selv, kolleger, 'systemet', osv. Denne mulighed for at få videregivet egne erfaringer med henblik på, at andre kan nyde godt af dem, er indlysende rigtig og samtidig inspirerende.
Paradokset er blot, at det, som man har beskæftiget sig med og været intenst optaget af i månedsvis, pludselig ikke lader sig formulere i ord, tal og tabeller. Hvordan kan man skabe orden i kaos og præsentere sine data så redeligt, at de kan vurderes af læseren på flere dimensioner: Pålidelighed, gyldighed og anvendelighed?
Sygeplejefaglige undersøgelser kan være meget forskellige, men arbejdsgangen eller metodikken omfatter almindeligvis følgende fire faser:
- problemformulering
- planlægning af undersøgelsen
- indsamling af data
- analyse, status og evaluering.
Resumé af undersøgelsens væsentligste resultater skal naturligvis rummes i artiklen til 'Sygeplejersken' – men læserens vurdering af resultaterne – herunder hvorvidt de kan anvendes i praksis, vil være afhængig af mange forskellige forhold – eksempelvis videnskabsteoretisk udgangspunkt, forforståelse og personlige faktorer. Undersøgelsens forfatter og projektleder arbejder naturligvis også ud fra en faglig referenceramme, der har været afgørende for forvaltningen af spændingsfeltet mellem problemformuleringen og den anvendte metode.
Derfor skal en redelig artikel suppleres med oplysninger af metodemæssig art fra de forskellige faser i en undersøgelse – eksempelvis:
- hvad var problemet? hvem var det et problem for?
- hvordan planlagdes undersøgelsen?
- hvordan samledes oplysningerne ind?
- hvor var der afvigelser mellem det planlagte og det, der faktisk skete? hvilken betydning har det for analysen? mv.
Læs tal og tabeller
Den daglige avis og tv-avis er fyldt med tal. Der argumenteres ved hjælp af tal og statistik. De fleste undersøgelser inden for det medicinske og sygeplejefaglige felt indeholder tal. Vi er med andre ord omgivet af tal – og dermed også en eller anden form for systematisering
Side 25
af oplysninger (eksempelvis gennemsnit, typetal, varians). Faktisk er opgaven med at skrive tabeller ikke så vanskelig endda – blot man går systematisk og logisk til værks, og da systematik og logik er helt centrale begreber, når medicinske eller sygeplejefaglige undersøgelser foretages, skal tankegangen blot fortsættes, når tabellerne konstrueres og tallene skrives. De fleste tabeller udformes efter samme princip, og når man har forstået det, er det relativt nemt både at læse og også skrive en tabel.
En redelig tabel skal se ud – og omfatte så mange oplysninger, at den kan læses for sig selv, dvs. uafhængig af teksten i artiklen. I tabellen i figur 1 ses en traditionel tabelskabelon, der indeholder en forspalte og et hoved samt nogle oplysninger, der er knyttet til disse. Endvidere er den forsynet med en overskrift, der siger, hvilke data, der indgår. I tabellens fodnoter, anmærkninger mv. kan anføres yderligere oplysninger.
Overskriften på tabellen i figur 2 fortæller, at den omhandler kvindelige og mandlige præster fordelt efter ægteskabelig stilling. I forspalten kan man se, at alle civilstandskategorier indgår: ugift, gift/samlevende, fraskilt/separeret og enke(mand). Tallene i tabellen er procenttal, og procentbasis, dvs. det totale antal personer, der er grundlag for procentberegningerne, er anført i sidste linie. Der indgår således 177 kvindelige præster og 167 mandlige præster. Anmærkningen fortæller, at en enkelt kvindelig præst har undladt at besvare spørgsmålet.
Når man skal læse tabellen, er det en god idé at se efter evt. mønstre i tabellen – hvor er det største tal, hvor er det mindste, er der et særligt mønster i fordelingen (fx stigninger i tallene for den ene gruppe og fald for den anden gruppe), er fordelingen den samme for kvinderne og for mændene – eller er der forskel?
De største tal i tabellen i figur 2 fortæller, hvad der er det mest almindelige, og de mindste fortæller, hvad der er det sjældneste. Rækkefølgen er ens for de to køn, selv om der er forskel på hyppighederne. I undersøgelsen konkluderes følgende: ''De allerfleste præster er gifte (eller samlevende), men det gælder i væsentlig højere grad for de mandlige præsters vedkommende. Her er den enlige præst næsten et særsyn. Blandt de kvindelige præster er der fire gange så mange ugifte og tre gange så mange fraskilte som blandt de mandlige præster.''
Figur 1. Tabelskabelonen
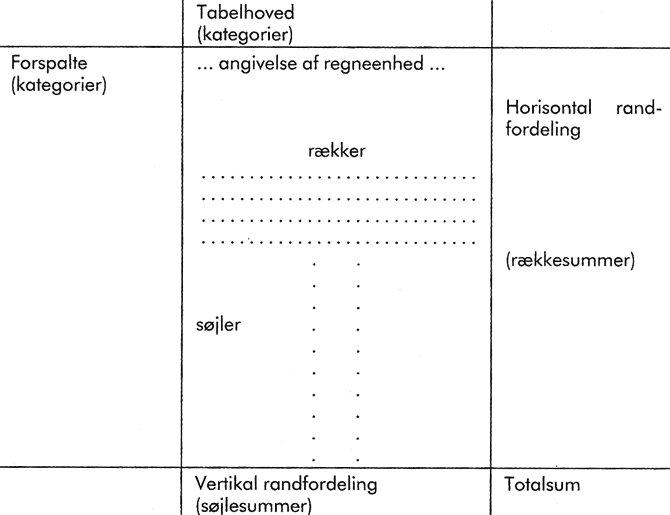
Anmærkning: (eksempelvis generelle, nødvendige oplysninger)
Noter: (eksempelvis specifik information om indholdet i de enkelte kategorier)
Kilder: (eksempelvis hvorfra kommer tabellens materiale?)
Figur 2. Eksempel på en simpel tabel
Fordeling af kvindelige og mandlige præster efter ægteskabelig stilling. Procent. (Boolsen, 1990)
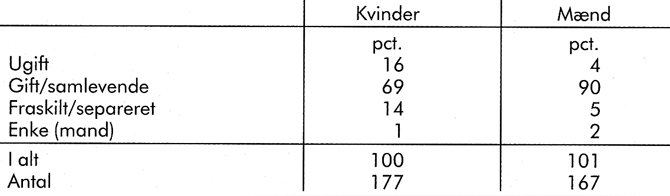
Anmærkning: Tabellen er taget fra en bog, der handler om ligestillingen mellem kvindelige og mandlige præster i den danske folkekirke. 200 kvindelige og 200 mandlige præster indgik i undersøgelsen; i tabellens sidste linie er anført, hvor mange henholdsvis kvindelige og mandlige præster, der besvarede det tilsendte spørgeskema.
Note: Der mangler oplysninger fra 1 kvindelig præst.
Kilde: Boolsen, Merete Watt: Ligestilling i folkekirken? Socialforskningsinstituttet, 1990.
Pas på procenterne
Der er ingen regler for, hvor små eller hvor store tal en tabel kan indeholde, men hvis datamaterialet alene omfatter en håndfuld personer, kan det godt virke noget besværligt eller kunstigt at se disse (få) personer sat ind i en tabel. Principielt er der ingen forskel på konstruktionen af tabeller med få eller mange observationer, men observationsmængden gør en forskel, når man giver sig til at regne videre – eksempelvis oversætte til procenter eller anvende statistiske test.
Antallet af personer, cases eller tilsvarende må som sagt godt være lille i en tabel – men det er ikke nødvendigt at oversætte et lille talmateriale til procenter. Faktisk er det ofte direkte misvisende; undersøgelsens resultater læses forkert, når én person eksempelvis fylder fem-ti procent eller mere.
Eksempel (figur 3, side 26): Hvis 60 procent af en gruppe patienter reagerer på en bestemt måde (A) på en behandling og de resterende 40 procent reagerer på en anden måde (B), vil man være tilbøjelig til at konkludere, at A er langt den almindeligste reaktion. Men hvis datasættet kun består af ti personer, betyder det, at seks personer reagerer med A og fire med B – og det giver et helt andet indtryk, selv om procenttallene er de samme. (Hvis målingerne på blot en eneste af patienterne med A-reaktionen er usikker, er det ensbetydende med, at der bliver lige mange i hver gruppe).
Nu tænker vi os, at de ti patienter forøges med én til 11 (kolonne 4 og 5). Den nye ekstra patient reagerer med B, og straks ser tallene
Side 26
noget anderledes ud – på de absolutte tal er der alene én patient til forskel, men i procenttallene er der ti procent forskel mellem tallene. (Den typiske reaktion er stadigvæk A i de to grupper – men det faktiske talgrundlag for denne konklusion er én patient). I tilfælde af at den nye patient reagerer med A, ser forskellen mellem A og B endnu større ud, når procenttallene betragtes: 64 procent over for 36 procent – eller 2/3 over for 1/3 (kolonne 6 og 7).
Én ekstra patient kan med andre ord forrykke hele procent-billedet, når det samlede antal patienter er meget lille.
I en redelig tabel, skal der være mere end 100 personer, førend procenter introduceres. (Læg mærke til, at mange – i fagtidsskrifter, aviser o.a. – er uenige med mig i denne betragtning. Prøv i fortsættelse heraf at vurdere ovennævnte argumentation på det konkrete materiale).
Figur 3

Læsevenlige tabeller
Det er bestemt ikke ligegyldigt, hvilken måde man præsenterer sine tal på. Store talmængder bliver lettere at håndtere, når de er procentfordelt, men måden at procentfordele på, er afhængig af den problematik, der er til drøftelse. Derfor skal man tænke sig godt om, inden man vælger blandt nedennævnte tre muligheder:
- horisontal procentfordeling med basis i rækkesumtallene
- vertikal procentfordeling med basis i søjlesumtallene
- procentfordeling med basis i totalsummen.
I en redelig tabel med procenter, skal procentbasis angives. Procentberegninger giver nemlig ofte anledning til mange misforståelser, og det er derfor vigtigt at angive procentbasis tydeligt, således at læseren kan udlede, hvad der har stået i tælleren, og hvad der har stået i nævneren, når procentberegningerne er udført.
Men procenter og procentberegninger giver anledning til at sige andre ting. I det følgende eksempel, har forfatterne procentfordelt 30 tilfælde af fysisk magtanvendelse over for otte børn. Materialet er næsten stillet op i en tabel, de 30 situationer er defineret på forskellig måde i teksten og derefter fordelt efter begrundelse for indgrebet:
Markere grænser: 43,33 procent Bremse handling: 36,66 procent Konflikt med andet barn: 20,01 procent.
Ud over at der (efter min vurdering, når vi taler om en redelig præsentation af undersøgelser) bør være mere end 30 tilfælde, når procenter beregnes, kan man også sige, at decimalerne er overflødige. Naturligvis er 43,33 procent en mere præcis angivelse end 43 procent, men i sammenhængen kan man sige, at det er ligegyldigt, om der står det ene eller det andet. Set ud fra et læsevenlighedssynspunkt er de afrundede tal at foretrække.
Procenter giver ikke altid præcis 100, når tallene lægges sammen. Sommetider er der tale om næsten 100 (99 procent) eller godt 100 (101 procent). I eksemplet her fordeler de 30 tilfælde sig med 13, 11 og 6. Procentberegningen giver 43,33, 36,66 og 20,0. Sammenlagt bliver det til 99,99 procent. Når de 20 procent har fået føjet 0,1 procent på, kan det skyldes forfatterens ønske om, at sammentællingen af procenterne skal give præcis 100. Ideologierne på området er forskellige. Personligt har jeg den opfattelse, at hvis sammenlægningerne af de beregnede tal ikke giver præcist 100, så gør det heller ikke noget.
Analyser og hypoteser
Når man beskriver analysens resultater, er det en god idé også her at gå systematisk og logisk til værks – og beskrive de enkelte metoder og rækkefølgen af dem – eksempelvis:
• hvordan er analysen gennemført? hvilke hypoteser kunne formuleres? hvilke hypoteser blev testet? hvilke statistiske test har været anvendt (og er forudsætningerne opfyldte)? hvilke konklusioner kan drages? hvor stor er usikkerheden på resultaterne? hvilke andre grupper kan analysens resultater generaliseres til?
Hypotesetestning er et større kapitel i enhver undersøgelse, ideologierne er mange, og derfor må en redelig præsentation omfatte oplysninger, der gør det muligt for læseren at vurdere metoderne og drage sine egne konklusioner.
Her vil jeg nøjes med at nævne nogle selvfølgeligheder, der nemt kan overses af begyndere – nemlig at de generelle retningslinier ved en redelig anvendelse af statistiske test handler om, at der skal være overensstemmelse mellem datas egenskaber og testens forudsætninger. Der er mange forskellige test til rådighed, og det gælder derfor om at vælge en test, hvis forudsætninger kan opfyldes af det foreliggende materiale. De hurtige små regnemaskiner har gjort det nemt at teste et materiale, men ofte viser det sig, at der overtestes – dvs. at der anvendes test, der ikke kan anvendes, fordi de er udviklet med henblik på andre situationer. Testresultaterne bliver derfor blot meningsløse tal i sammenhængen.
Det hænder også, at der gennemføres test- eller korrelationsberegninger på meget små data-materialer (eksempelvis færre end 30). Her skal man igen vurdere, om det giver mening. Tallene kan beregnes, men resultatet kan være behæftet med så stor usikkerhed, at den hypotese, som man tester, hverken kan af- eller bekræftes.
Udvælgelsesmetode
Statistiske test forudsætter ofte store talmængder, og det virker umiddelbart logisk at antage, at jo større det talmateriale er, der ligger til grund for beregningerne, desto mere sikkert kan vi udtale os.
Side 27
Det hænder, at jeg får stillet spørgsmål som ''hvor mange skal stikprøven omfatte for at være repræsentativ?'' Men det er faktisk et vrøvlet spørgsmål, fordi repræsentativitet og stikprøvestørrelse har ikke noget med hinanden at gøre.
Repræsentativitet har noget med udvælgelsesmetoden at gøre. En repræsentativ stikprøve er et minibillede af den befolkning, som den er taget fra, og hensigten med en repræsentativ stikprøve er, at resultaterne af undersøgelsen kan generaliseres til hele den befolkning, stikprøven er taget fra.
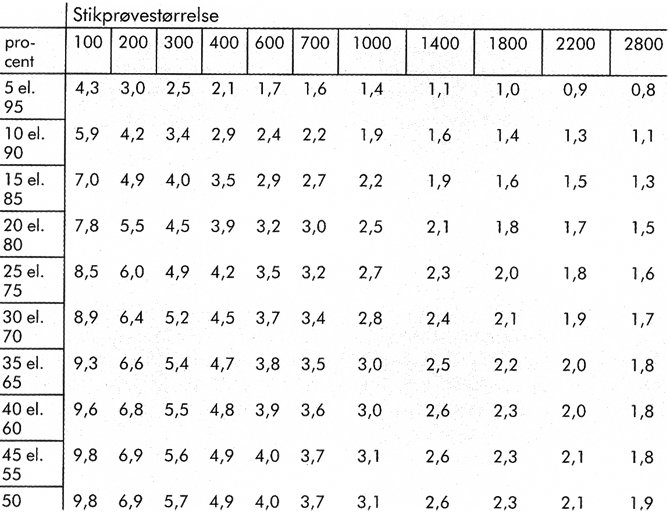
Undersøgelser, hvor personerne er udvalgt repræsentativt, er behæftet med en statistisk usikkerhed, der bliver større, jo mindre udsnittet er og omvendt mindre, jo større udsnittet er. – Læg mærke til, at udvælgelsesmetoden (igen) er afgørende for den statistiske (u)sikkerhed. Derfor er udvælgelsesmetoden central, når et materiale beskrives redeligt. Der hersker ofte stor tvivl om dette emne. Tabellen i figur 4 indeholder den statistiske usikkerhed på en række resultater (tabellens forspalte). Der er (i tabellens hoved) angivet forskellige stikprøvestørrelser.
Ved hjælp af tabellen kan man beregne, hvor stor den statistiske usikkerhed er på et givet resultat. Sikkerhedsgrænsen eller signifikansniveauet i den viste tabel er på 95 procent, dvs. der er 95 procent sandsynlighed for at have ret og fem procent sandsynlighed for at tage fejl. (Andre sikkerhedsgrænser kan naturligvis vælges – men denne anvendes ofte inden for samfundsvidenskaberne).
Tabellen i figur 4 kan bruges på følgende måde: Man ved fra en undersøgelse af 1.000 personer (der er udvalgt repræsentativt), at 25 procent har været syge inden for den seneste måned. Man er nu interesseret i at vide, hvor stor en del af hele befolkningen der med 95 procent sandsynlighed kan siges at have været syge i den pågældende periode.
Denne andel af befolkningen udtrykkes ved et interval omkring de 25 procent fra stikprøven. I tabellens forspalte vælger man den procent, der svarer til den andel, man har fundet i stikprøven, i dette tilfælde 25 procent. I denne vandrette linie aflæser man under 1.000 personer, som står i tabelhovedet, at intervallet hedder 2,7 procent.
I eksemplet vil den andel af befolkningen, der har været syge inden for den sidste måned således med 95 procent sikkerhed ligge mellem 22,3 procent og 27,7 procent (2,7 procent på begge sider af 25 procent).
Hvis man derimod kun har undersøgt 100 personer (ligeledes repræsentativt udvalgt) og konstateret, at 25 procent har været syge inden for den seneste måned, ser tallene noget anderledes ud. I tabellens forspalte vælger man igen den procent, der svarer til den andel, man har fundet i stikprøven, i dette tilfælde 25 procent. I denne vandrette linie aflæser man under 100 personer, som står i tabelhovedet, at intervallet hedder 8,5 procent.
I det nye eksempel vil den andel af befolkningen, der har været syge inden for den sidste måned således med 95 procent sikkerhed ligge mellem 16,5 procent og 33,5 procent (8,5 procent på begge sider af 25 procent).
Den statistiske usikkerhed på den fundne fordeling af syge er med andre ord større, jo mindre stikprøven er – og omvendt mindre, jo større stikprøven er. Men forudsætningen for at kunne anvende tabellen er, at stikprøven er udvalgt tilfældigt, således at den kan antages at udgøre et minibillede af hele befolkningen.
Afslutningsvis skal siges, at man naturligvis skal kende sit data-materiale for at kunne præsentere det redeligt, det kan efter min vurdering ske ved, at man oplyser om de anvendte metoder og de fundne resultater. Ovennævnte pointer kan være med til at præsentere materialet overskueligt, præcisere sammenhænge og forudsætninger – alt sammen præmisser, der er nødvendige for den læser, der ønsker at tage stilling til undersøgelsens pålidelighed, gyldighed og anvendelsesområde.
Figur 4. Den statistiske usikkerhed
Merete Watt Boolsen er ansat på Danmarks Lærerhøjskole og har et eksternt lektorat i faget 'Metode' på Københavns Universitet.